

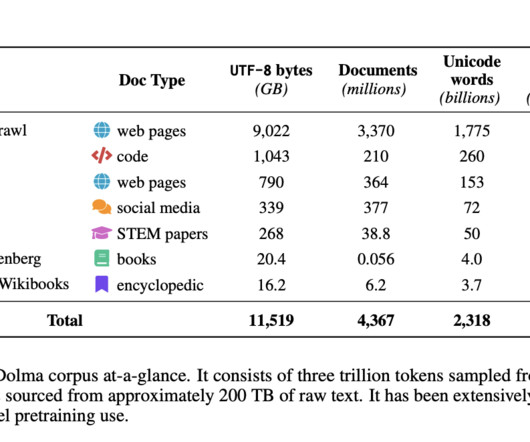
Meet Dolma: An Open English Corpus of 3T Tokens for Language Model Pretraining Research
Marktechpost
FEBRUARY 8, 2024
Large Language Models (LLMs) are a recent trend as these models have gained significant importance for handling tasks related to Natural Language Processing (NLP), such as question-answering, text summarization, few-shot learning, etc. A team of researchers have discussed transparency and openness in their recent study.
















Let's personalize your content