

Improve LLM performance with human and AI feedback on Amazon SageMaker for Amazon Engineering
AWS Machine Learning Blog
APRIL 24, 2024
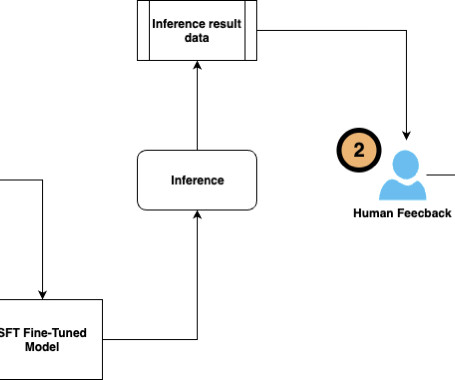
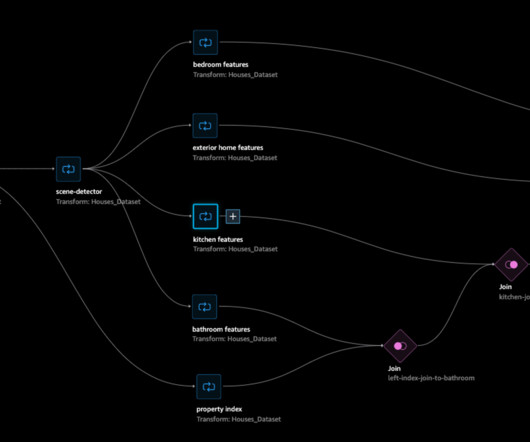
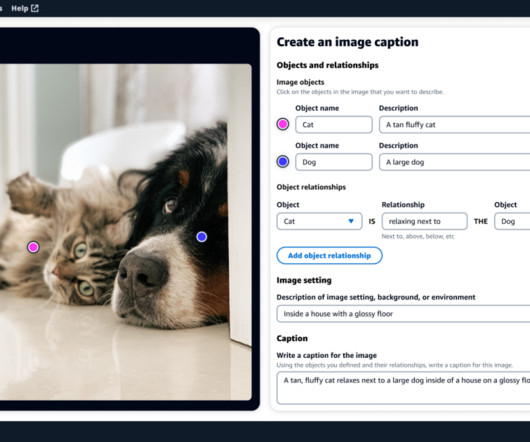
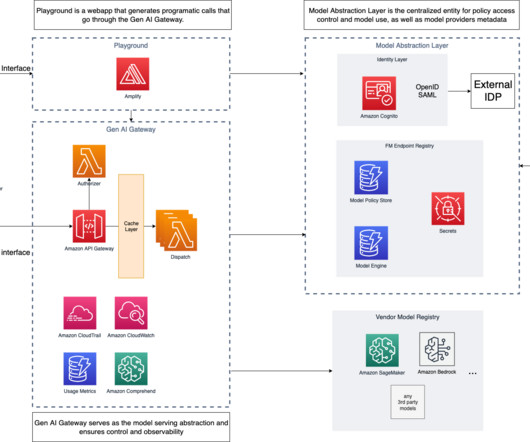
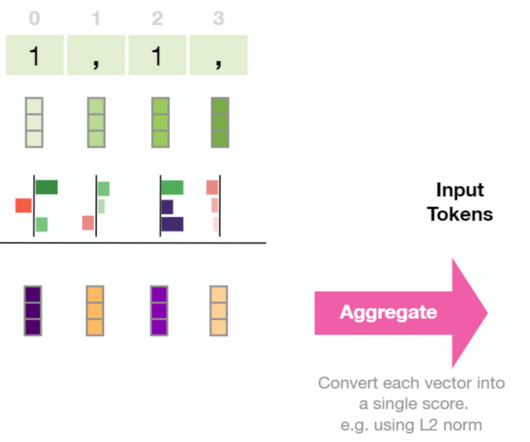
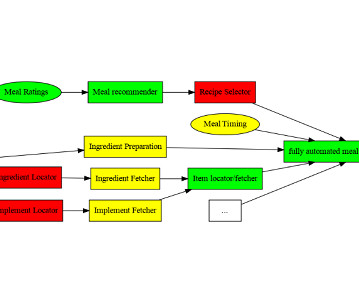
In this post, we share how we analyzed the feedback data and identified limitations of accuracy and hallucinations RAG provided, and used the human evaluation score to train the model through reinforcement learning. To increase training samples for better learning, we also used another LLM to generate feedback scores.































Let's personalize your content