


What Is Rum data and why does it matter?
IBM Journey to AI blog
DECEMBER 18, 2023
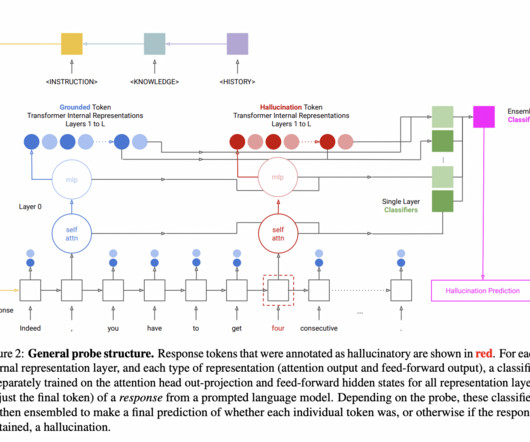
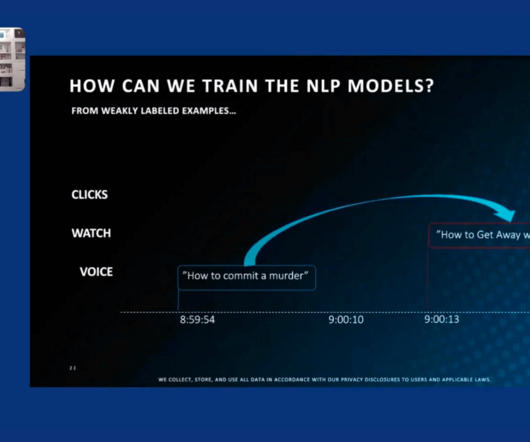
What is RUM data? Contrary to what you might think, RUM data isn’t a performance indicator for Captain Morgan, Cuban tourism or a Disney film franchise. Real User Monitoring (RUM) data is information about how people interact with online applications and services. Are there alternatives to RUM data? Actually, yes!





































Let's personalize your content