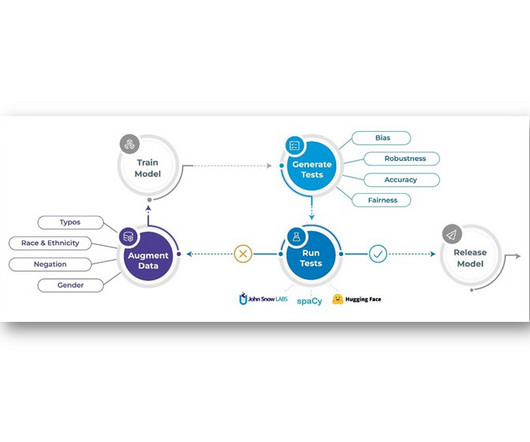
Writing Robust Tests for Data & Machine Learning Pipelines
Eugene Yan
SEPTEMBER 3, 2022
Or why I should write fewer integration tests.

 writing testing-pipelines
writing testing-pipelines 
Eugene Yan
SEPTEMBER 3, 2022
Or why I should write fewer integration tests.

AI News
MAY 3, 2024
“Our AI engineers built a prompt evaluation pipeline that seamlessly considers cost, processing time, semantic similarity, and the likelihood of hallucinations,” Ros explained. ” Recognising the critical concern of ethical AI development, Ros stressed the significance of human oversight throughout the entire process.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Unite.AI
JUNE 7, 2023
Founded in 2006, it provides SaaS application security that integrates application analysis into development pipelines. The ideal process includes testing in the IDE and the CI/CD pipeline. For years, software security has revolved around testing to find issues, but for every issue found, there is a manual task to fix.

Towards AI
APRIL 7, 2024
It is the data we feed it with and a reliable pipeline. Overall, we need high confidence in our pipeline, model, and understanding of the problem and data. However, we cannot test many of the above points with unit tests as in traditional software development. A good trick is to write specific functions first.
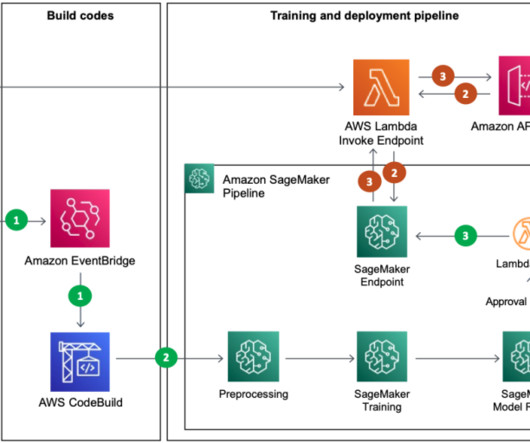
AWS Machine Learning Blog
MAY 16, 2024
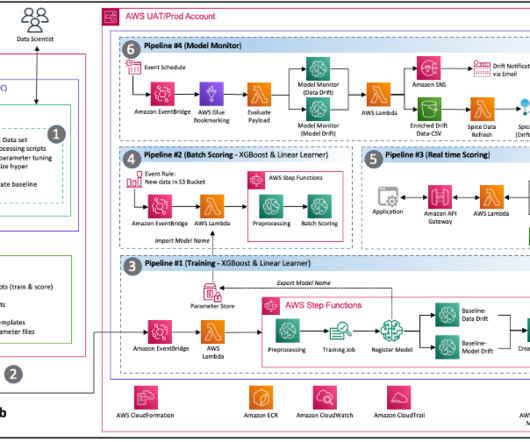
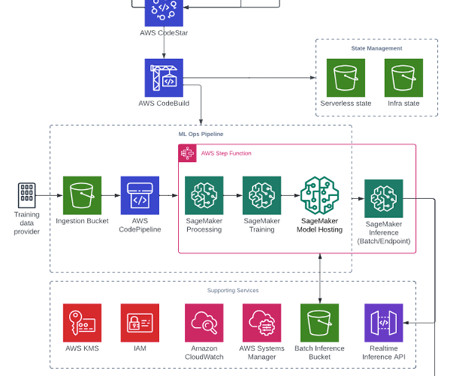
Training pipeline and model deployment The model training and deployment phase consists of the following steps: After the training data is uploaded to Amazon S3, CodeBuild runs based on the rules specified in EventBridge. For this reason, we built the MLOps architecture to manage the created models and provide real-time services.

AI News
NOVEMBER 13, 2023
Beyond code analysis, it supports planning, security issue comprehension and resolution, troubleshooting CI/CD pipeline failures, aiding in merge requests, and more. The State of AI in Software Development report by GitLab reveals that developers spend just 25 percent of their time writing code.

IBM Journey to AI blog
NOVEMBER 14, 2023
Moreover, 36% of developers struggle with the collaboration between development and IT Operations, leading to inefficiencies in the development pipeline. To compound these issues, repeated surveys highlight “testing” as the primary area causing delays in project timelines. How does Wazi as Service help drive modernization?

Expert insights. Personalized for you.



















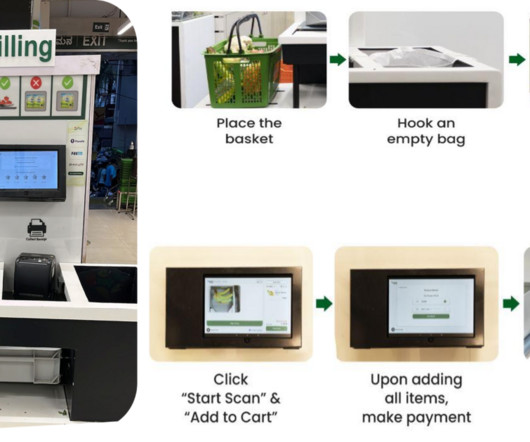






Let's personalize your content