

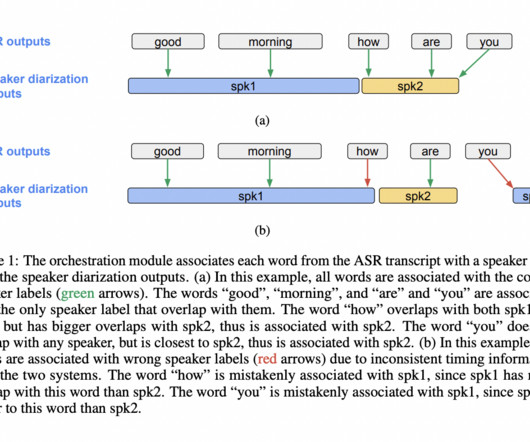
Google AI Researchers Introduce DiarizationLM: A Machine Learning Framework to Leverage Large Language Models (LLM) to Post-Process the Outputs from a Speaker Diarization System
Marktechpost
JANUARY 12, 2024
In audio processing, speaker diarization is a critical yet challenging task. This technique, pivotal in discerning individual voices in multi-speaker environments, holds immense value across various applications. These systems typically fall into two categories: modular and end-to-end systems.



































Let's personalize your content